Part 6: From Magic Sauce to Hard Reality: The AI Security Startup ConundrumLink
To really dig into why the middleware information security AI as a service startup is setup for failure and guaranteed to financially fail if the stock isn’t the product; we aren’t done yet.
Systems Science Perspective on LMs
As mentioned above, the "long tail" of potential prompts that LMs might encounter represents a vast, complex space that no single model can be expected to cover comprehensively. This highlights a key principle in systems science: the characteristics of intricate systems, such as large language models (LMs), manifest unexpectedly and defy complete prediction or comprehension when only examining their separate elements, like the training data or prediction mechanisms used within the model.
The resulting property of hallucination in responses to unforeseen prompts underscores the limitation of LMs in dealing with complexity and their lack of adaptability when encountering new or rare inputs. Systems science suggests enhancing system adaptability through more dynamic learning processes that allow the model to adjust its behavior based on new information or feedback, thus reducing the incidence of hallucinations. Which is where we see much research being done by academia, governments, and the private sector.
Perspective on Future Model Architectures
In these information security use cases, these systems will need to move towards models that function more like human reasoning (System 2 thinking) which involves a paradigm shift from the current autoregressive token prediction models to ones capable of abstract reasoning and planning. For instance, right now, have your LM tell you how to get to Hong Kong. Recursively, you can push it down to the individual muscle fiber twitch → stand up → open door → etc… But they can’t handle a simple multi-user-dungeon where you need to look around and reason how to exit your room before you can get to the transit to head to the airport. This architecture shift entails designing infosec models that can operate within an "abstract representation space," optimizing answers based on a deeper understanding of the question's context, rather than just generating the next probable token. For instance, the context behind the Code Red Worm would make it clear it has nothing to do with Remote Desktop Services. Or a similar ask where the context of a Web Application Firewall at the customer’s site would allow one to proactively create a WAF rule to prevent an infection in addition to the detective sigma rule to determine if one is or was infected. But that requires A LOT of energy and human reasoning augmentation to enable this very simple step. Which is why many are looking at how physics approached these challenges.
This effort/energy approach aligns with the principles of computer systems science, especially in terms of creating more sophisticated, efficient, and adaptive computational models. The transition to energy-based models (EBMs are a type of canonical ensemble formulation of statistical physics)
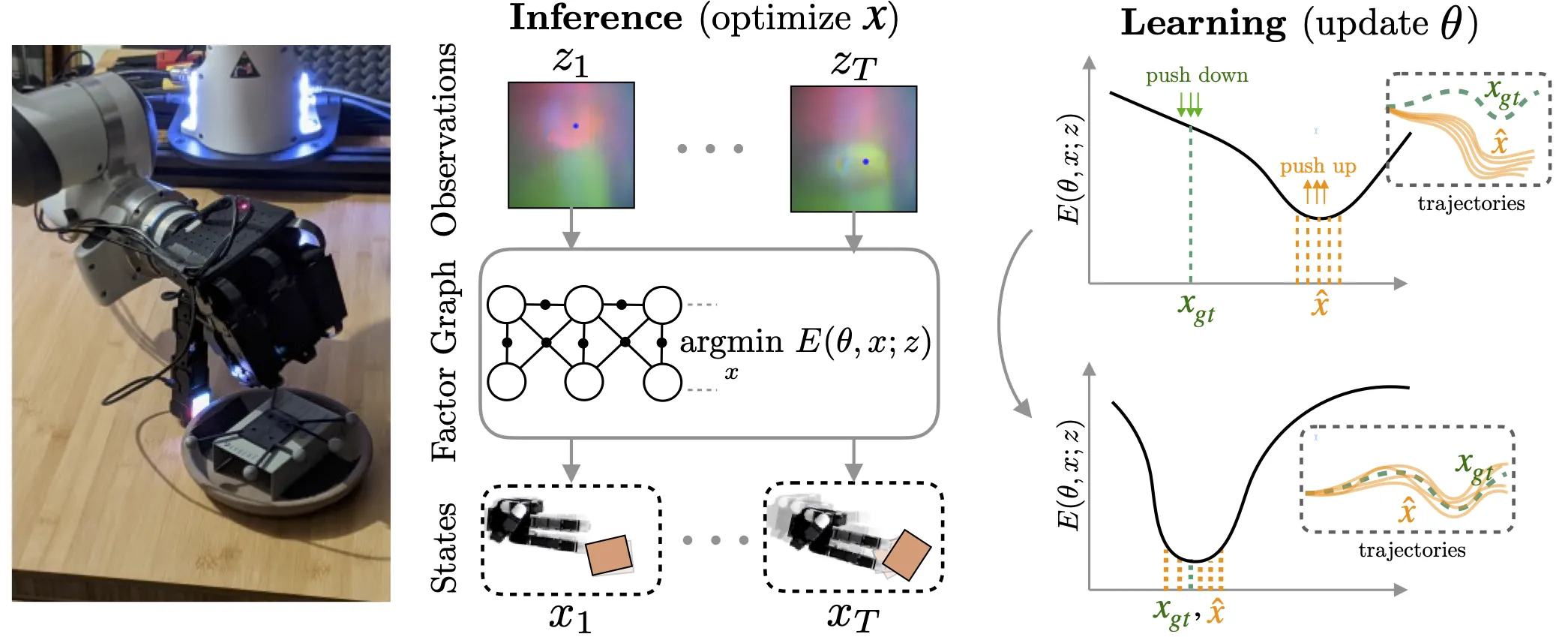
that optimize over an abstract representation space implies a move towards systems that can infer latent variables and relationships, akin to probabilistic models or graphical models in traditional machine learning.
This requires the system to understand the context and semantics at a much deeper level, using a scalar output as a measure of the answer's appropriateness to the given prompt.
Information Security optimization problems, especially reactive domains such as vulnerability and incident management, involves finding the best representation of an answer within this abstract space that minimizes the difference (or energy) between the predicted answer and what would be considered a correct or appropriate answer. This process necessitates a more nuanced understanding of language, context, and even intent than current LMs possess, pointing towards the integration of more advanced machine learning techniques, such as deep learning, reinforcement learning, and unsupervised learning, into the architecture of future language models.
Turing Completeness and Beyond
The ultimate goal is to achieve Turing completeness in dialogue systems — a state where the system can execute any computation that a Turing machine can, given adequate resources like unlimited ticker tape or an infinite data store. This would entail the ability to not just mimic human-like text generation but to exhibit human-like reasoning, understanding, and problem-solving capabilities.
Achieving this goal involves overcoming significant challenges in computational theory, model architecture, and algorithm design. It requires a fundamental rethinking of how we model language and thought processes, moving beyond current paradigms towards systems that can genuinely understand and interact with the world in a manner akin to human cognitive processes. Ask yourself - does your AI security startup seeking funding have the academic skillsets and experiences to make novel, potentially Nobel winning breakthroughs with $10,000,000,000 in Nvidia H100s to run their experiments and eventual services on? Yet they are asking you to invest $150,000 for a 0.5% dilutable stake. Where is the other $9,999,850,000 to pay for the lab hardware coming from?
Ultimately, the challenges an information security startup involving LMs in their magic sauce offerings encapsulates a forward-looking perspective on the institutions’ development of LLMs, emphasizing the need for systems that can reason, plan, and adapt. From the integration of systems science principles for managing complexity and adaptability to the application of advanced computational models for abstract reasoning, the future of LLMs promises a convergence of interdisciplinary approaches to create models that more closely mirror human cognitive capabilities. We will get there. But not with today’s hardware nor tomorrow’s algorithms. Nor with the big bests and backing various VCs are able to provide. Why? Why touches upon several advanced concepts in machine learning and artificial intelligence, particularly focusing on optimization processes, gradient-based inference, and energy-based models. Let's expand on these topics to deepen the understanding.