Part 4: AI's Fantasy vs. Reality: Navigating the Wonderland of Language ModelsLink
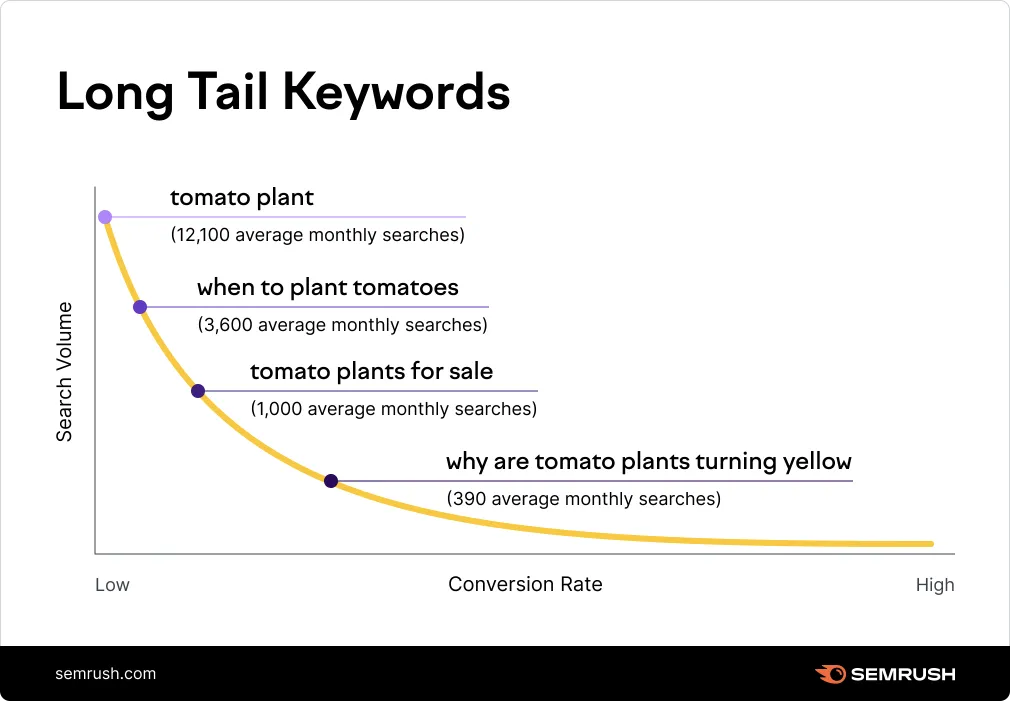
Another aspect is the design of adaptive generation strategies that adjust based on the context or the detected quality of the output so far. This might involve altering the prediction confidence thresholds in areas where the model is less certain, or leveraging external data sources to fill in gaps in the model's knowledge. While great to utilize, these approaches are extremely limited in effectiveness due to the distribution of potential inputs to these models. More on this below as there is a VERY long tail in this area of research. For instance, look at this simple search related to tomato plants. A lot of inputs involving tomato plants yet few involve turning yellow vs. approaching zero inputs for the input “tomato plants ate Alice in Wonderland?”

Scalability and Evolution
An interesting approach to managing the long tail distribution curves as well as not requiring a complete training run yet again because someone mispelled Code Red in a dataset involves scaling the systems and striving towards evolution-like attributes. Complex systems engineering emphasizes the importance of designing systems that are not only scalable but can also adapt to new challenges over time. This means creating LMs that can handle increasing volumes of data, more complex queries, and generate longer, more nuanced texts without a corresponding increase in errors or processing time.
Modularity plays a key role here, allowing different components of the LM to be updated or replaced without overhauling the entire system. This could involve integrating new error correction algorithms as they become available, or updating the token prediction mechanism to take advantage of advancements in natural language processing.
There is interesting academic research anticipating future expansions, such as incorporating additional data sources on the fly or languages, and adapting to new applications beyond text generation, like automated reasoning. This foresight ensures that the LM can grow in capability and continue to meet users' needs without requiring frequent, disruptive changes to the core architecture. Especially as error rates exceed systems tolerances. When these error rates exceed tolerances, these errors are commonly referred to as hallucinations.
Another problem, especially in legal contexts such as incident response and vulnerability management, is a phenomenon known as "hallucinations" in large language models (LMs), where the model generates information or data that isn't grounded in the input it received or in factual accuracy. This issue is central to understanding the limitations and challenges in designing and working information security problems with LMs. Let's expand on the concepts they touch upon:
Hallucinations in Large Language Models
What are Hallucinations?
- Hallucinations refer to instances where an LLM produces output that is unconnected to the input data or reality, essentially "making things up." This can range from slightly inaccurate details to entirely fabricated statements or narratives. These errors are particularly concerning when LMs are used in contexts where accuracy and reliability are paramount, such as in information security, software engineering, critical computing & workloads, finance, healthcare, the battlefield, critical infrastructure, academic research, or healthcare.
Why Do Hallucinations Occur?
- Hallucinations primarily occur due to the inherent limitations in how LMs understand and process language. Despite their vast training data, LMs don't "understand" content in the way humans do; they identify patterns in data and generate outputs based on statistical probabilities as mentioned previously. When an LLM encounters scenarios that are poorly represented in its training data or highly ambiguous inputs, it's prone to "guessing," leading to potential inaccuracies or hallucinations.
Autoregressive Prediction and Error Propagation
Error Propagation and Drift
- Every token generated carries a risk of being incorrect or not the optimal choice in context. Although each individual mistake might be minor, their effects are cumulative. The concept of "drift" refers to the gradual departure from accurate or relevant content as the generation process continues, especially in longer text outputs. Because each new token depends on the sequence generated thus far, errors can compound, leading to significant deviations from reasonable or factual outputs.
Fundamental Flaw or Inherent Challenges to Overcome?
Assessment of the Issue
- The issue of hallucinations and drift are fundamental flaws in the design of LLMs when these models are utilized in services that require >60% accuracy. This perspective underscores the challenges in creating models that can reliably produce accurate and coherent long-form content without supervision or correction.
Addressing the Challenge
- Improving LLMs to minimize hallucinations involves several strategies, including refining training datasets to cover a broader and more diverse range of scenarios (which will eventually lead to a giant lookup table, not a model…), enhancing models' ability to check their outputs against verified information sources, and developing more sophisticated mechanisms for understanding context and relevance.
The "Gravitational Pull" Towards Truth
In the VC community & poorly trained computer scientists and mathematicians; there is a significant influential "gravitational pull" towards the truth reflecting an optimistic view that if a training set is sufficiently large and diverse, an LM will naturally gravitate towards generating accurate and truthful responses. This hope is grounded in the assumption that the truth is well-represented in the data the model has been trained on. However, the reality of how LMs work complicates this assumption.
Curse of Dimensionality
The "curse of dimensionality" is a concept from computer science that refers to the exponential increase in volume associated with adding extra dimensions to a mathematical space. In the context of LLMs, this refers to the vast, nearly infinite set of possible prompts (or inputs) the model might encounter. Despite a comprehensive training dataset, the space of potential inputs and the corresponding appropriate outputs is so large that the model can only be directly trained on a tiny fraction of all possibilities. For example, is this a dog or cat? When more dimensions are added, the end result in the image below shows it is neither because the data is further spread out from 0 (No) to 1 (Yes) and nothing is in the selection box.
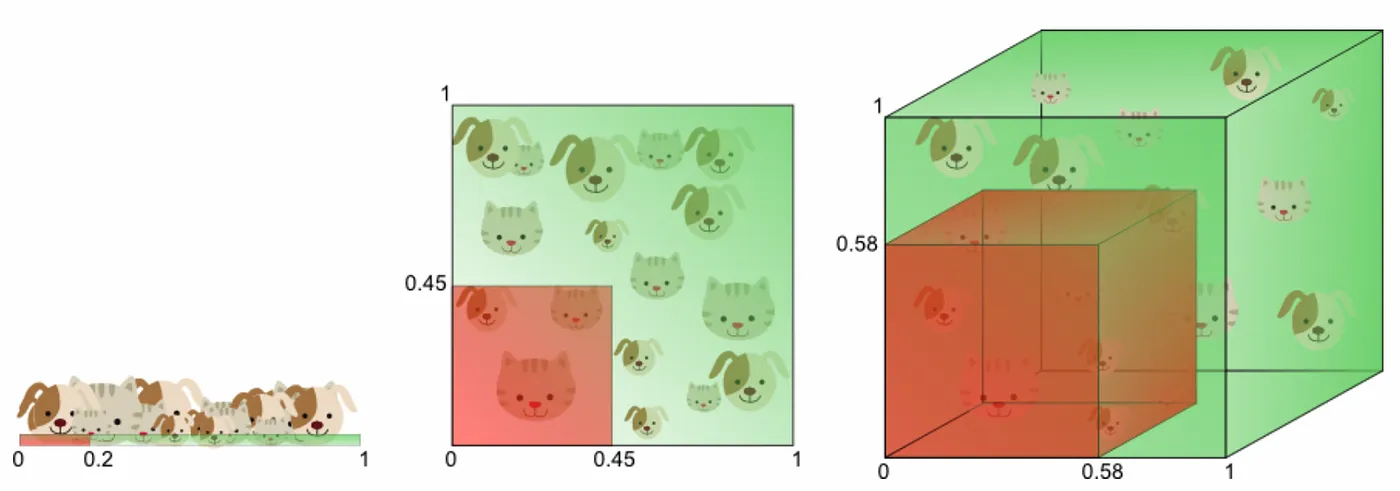
This situation challenges the idea of a model naturally gravitating towards truth simply because of a large and diverse training dataset. The reality is that the model's performance significantly drops off when faced with prompts that deviate even slightly from its training data, highlighting a fundamental limitation in its ability to generalize from known to unknown contexts, IE prompts outside the input’s long tail of distribution like “tomato plant ate Alice in Wonderland?” mentioned previously.
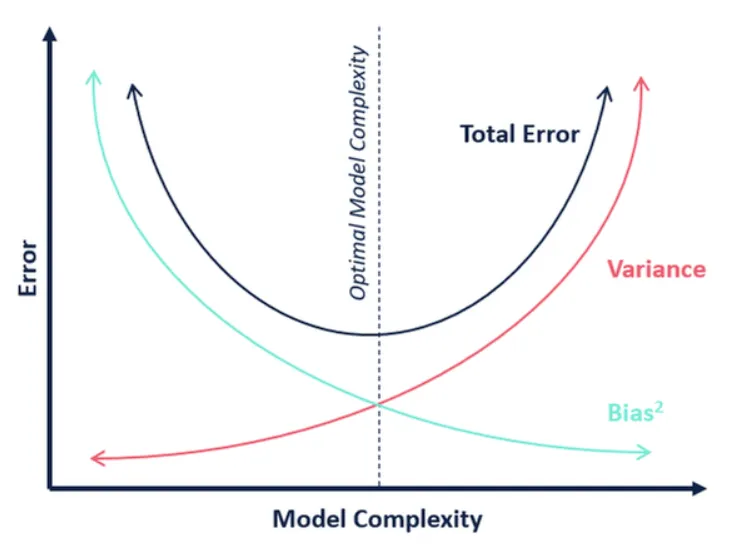
Which is why the LM creators aim for that magical sweet spot, unlike Alphabet’s recent Gemini launch where the Error and Bias numbers were acceptable to them, yet not acceptable to the users who asked simple factual questions like the one below

While it could be argued that a native american is a founding father of America, the other answers in their contexts are biased and in error. There is 0% probability the images for the Pope and 3 other founding fathers is correct. Approaching but never hitting 0%, the vikings may had a non-white member in some arcane historical context involving nomadic travelers. So the best answer to put forth far up and to the left on the above chart? Which gets us to tuning these models for information security related needs so optimal model complexity gets us closer to an acceptable error rate, limited bias with only an exponential increase in error rates and variances.